 If you’ve ever wrestled with the heavy computational load of tuning large language models (LLMs), you’re not alone. With models that pack over a billion parameters, traditional fine-tuning can be both slow and resource-hungry, especially on local hardware.
If you’ve ever wrestled with the heavy computational load of tuning large language models (LLMs), you’re not alone. With models that pack over a billion parameters, traditional fine-tuning can be both slow and resource-hungry, especially on local hardware.
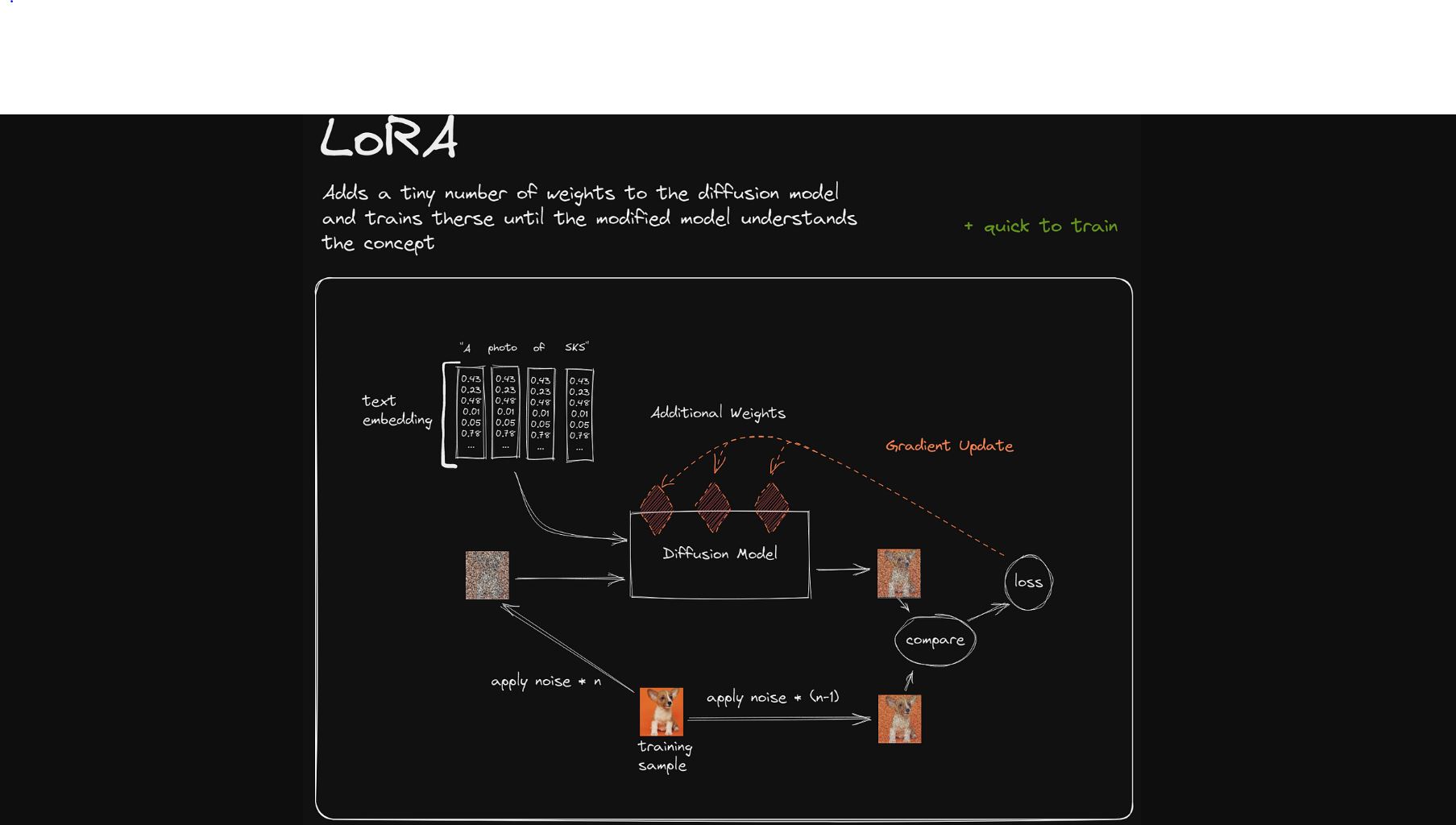
One practical approach to ease this challenge is Low-Rank Adaptation (LoRA). By factorising a large weight matrix into two slimmer ones, LoRA dramatically cuts down the number of parameters—for example, trimming a 67‑million-parameter matrix down to just 131,000. While this may slightly impact precision, the trade-off is often more than worth it.
LoRA also streamlines backpropagation by reducing the number of gradients that need computing. It starts by initialising one matrix with a Gaussian distribution and sets its companion matrix to zero, creating a stable base for fine-tuning.
Taking this a step further, QLoRA adds quantisation to the process. By compressing 32‑bit floats to 16‑bit, it further cuts memory demands without sacrificing model performance—a smart tweak for anyone looking to optimise resource usage.
Another clever feature of LoRA is the use of adapters—compact matrix pairs that let a single large model handle multiple tasks. Imagine a chatbot that can effortlessly switch from mimicking a favourite fictional character to adopting a different persona, all by swapping out its adapters. This method spares you from storing multiple full-sized models for different functions.
There’s also prefix-tuning, which installs adapters directly into the transformer’s attention layers without altering the model’s internal structure. Although it involves fewer trainable parameters, LoRA tends to be the go-to choice due to its overall efficiency.
In practical terms, embracing LoRA and QLoRA means you can fine-tune LLMs more quickly and efficiently—saving both time and computational resources while boosting memory efficiency. This optimisation is opening new doors for creating adaptable, powerful AI systems that keep pace with your needs.






