 If you’ve ever wrestled with managing interconnected records, you know that entity resolution (ER) is both a vital tool and a potential headache. At Tilores, we keep things straightforward by modelling entities as graphs—nodes represent records, and edges represent matches based on specific rules. This approach offers flexibility and precision, but when the graphs get dense, storage and computation can become a real challenge.
If you’ve ever wrestled with managing interconnected records, you know that entity resolution (ER) is both a vital tool and a potential headache. At Tilores, we keep things straightforward by modelling entities as graphs—nodes represent records, and edges represent matches based on specific rules. This approach offers flexibility and precision, but when the graphs get dense, storage and computation can become a real challenge.
Imagine a scenario where you record an edge as “a:b:R1” every time a rule links record ‘a’ to record ‘b’. If multiple rules apply, you add more edges. While a simple list might work for small datasets, using an adjacency list can help optimise storage efficiency.
Keeping every edge in view isn’t just for archival purposes. It builds traceability, so you can see exactly why certain records are grouped, and it supports deep analytics by revealing patterns in rule effectiveness and data similarity. Furthermore, complete edge records mean that if you need to delete or recalc data, everything remains clear and manageable.
Scaling this up, however, introduces a problem. When each new record connects with all previous ones, you’re looking at quadratic growth. For instance, an entity with 1,000 records might create nearly half a million edges, which can quickly overwhelm system resources.
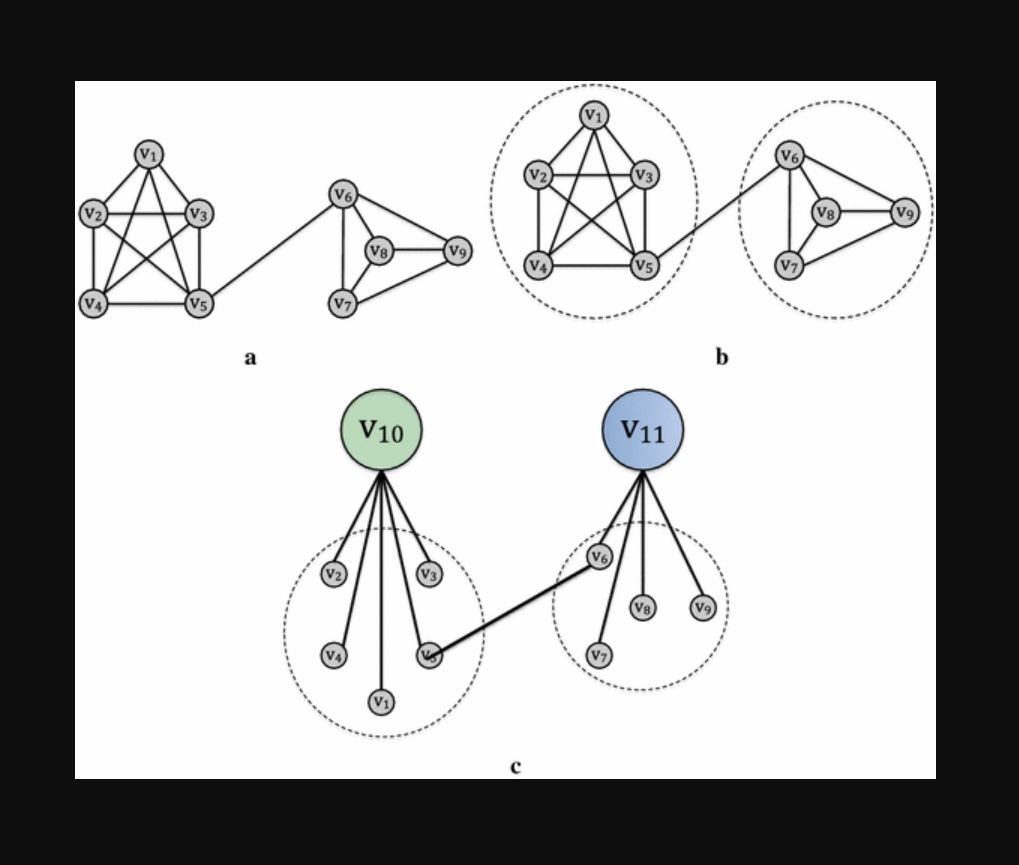
This is where Clique-Based Graph Compression (CBGC) makes a difference. A clique is simply a complete subgraph where every node connects to every other node. The beauty of this method is best seen when a group of connected nodes—say, a triangle connecting three records—gets compressed into a single representation. For example, instead of listing edges like “a:b:R1”, “a:c:R1”, and “b:c:R1”, you can store the compressed version as {“R1”: [[“a”, “b”, “c”]]}.
Even in larger graphs, such as complete subgraphs with six nodes, a compressed format can reduce what would otherwise be 15 separate edges into a neat list of nodes paired with a rule ID. In real-world applications, while not every record will be connected, identifying and storing these larger cliques greatly cuts down the total edge count. One client, for example, saw a 99.7% reduction in edge storage by swapping thousands of individual edges for a few hundred cliques and sparse connections.
Another benefit of CBGC is how it speeds up performance—especially during record or edge deletion. When an edge is cut, a strong entity resolution engine will segregate parts of the graph into separate groups. Typically, a connected components algorithm handles this grouping. Since you don’t have to traverse every edge within a clique, operations become quicker and simpler.
Of course, there’s a trade-off. Identifying cliques—especially the largest ones—can be computationally demanding. However, using approximate methods such as greedy heuristics usually offers results that are more than sufficient for real-world needs. CBGC recalculations only kick in when the number of entity edges exceeds certain thresholds, striking a careful balance between compression efficiency and processing cost.
While complete subgraphs are common in entity resolution, there’s room for further optimisation. Recognising and storing patterns like stars or paths can reduce the workload even more, allowing for streamlined and efficient data management.
By embracing clique-based compression, you can significantly cut down on storage while boosting performance in your entity resolution tasks. It’s a practical technique that, with the right engineering strategies, can scale alongside your data without overwhelming your system.






